



The central unifying idea behind many technology trends today is acknowledging that every company is becoming a software company. While organizations modernize their infrastructure and applications with cloud and microservices-based architecture, their data platforms haven’t kept pace. Traditional data platforms were designed decades ago in the pre-cloud era and simply don’t work for modern environments. They are slow, siloed, expensive to scale and complex to operate. Domain-specific point solutions create data fragments by only capturing partial data sets. Legacy approaches involve schema requirements on ingestion and indexes to organize data, making them slower.
While easy to get started, open-source solutions take substantial heavy lifting to scale, draining precious engineering resources. The combined weight of terabytes of data ingestion into a monolithic legacy solution with frequent access and concurrent queries could make it unresponsive and halt engineering productivity. You will end up spending more time creating indexes, re-indexing, sharding, re-sharding, provisioning compute and storage than finding the root cause of performance issues.
Legacy solutions have a tight coupling of compute and storage, so they can’t be scaled independently, resulting in significantly underutilized infrastructure. These inefficiency taxes are often passed on to customers increasing the total cost of ownership.
A New Approach is Needed
Modern data analytics platforms need the ability to handle LIVE data. We believe that data is dynamically changing, evolving, and growing, and it should be ingested once, combined, enriched, transformed, and be available for all use cases. Most importantly, businesses get value from deriving actionable, real-time insights from data across all time periods. Data platforms must be easy to operate and scale, designed and built for efficiency to deliver lower total cost of ownership while making security the first priority.
The DataSet Difference
DataSet is disrupting the massive data analytics market. Simply put, we enable our customers to derive value from all types of data across all time periods – streaming or historical – in real-time and at scale. LIVE data is necessary because success in the digital world depends on how quickly data can be collected, analyzed and brought to action. The faster the speed of data-driven insights, the more agile and responsive a business can become. DataSet enables teams to achieve an unparalleled combination of:
- Peak Performance: Data is available to query instantaneously after ingest within seconds and queries return in milliseconds even at a petabyte-scale. That’s fast, blazing fast.
- Effortless Scalability: DataSet elastically scales to practically unlimited scale. No need to rebalance nodes, manage storage, or allocate resources. As one of our customers put it - it just works!
- Lower TCO: Delivered as a cloud-native service, DataSet lowers the total cost of ownership by orders of magnitudes. DataSet provides unprecedented value at an unprecedented cost.
At the heart of it sits our unique architecture that combines high performance, low overhead index-free design and massively parallel processing that unlocks an unmatched data experience.
- Schema-Less Ingestion: Data comes in many different forms - structured, semi-structured or unstructured. DataSet offers enormous flexibility in data collection and ingestion without any processing overhead of schema evaluation.
- Streaming Engine: As the data is streaming through the system, the Streaming Engine creates materialized views for repeat queries, so high-res dashboards refresh, accurate alerts fire and automation tasks trigger within seconds. Unlike traditional time-series databases, the Streaming Engine supports unlimited data dimensions and high-cardinality analytics in real-time.
- Index-Free Design: Indexing is a traditional approach to organizing data. Indexes cause overhead during ingestion and retrieval as well as unnecessary resource consumption to build and rebuild indexes.
DataSet uses a columnar data format eliminating the need to maintain index clusters, re-indexing and re-sharding storage. - Massively Parallel Query Engine: DataSet’s query engine uses horizontal scheduling, devoting the entire cluster – every CPU core on every compute node – to one query at a time. This simple raw horsepower – the same approach used by Google web search – provides unprecedented performance, significantly increases resource utilization, and thus delivers cost-efficiency.
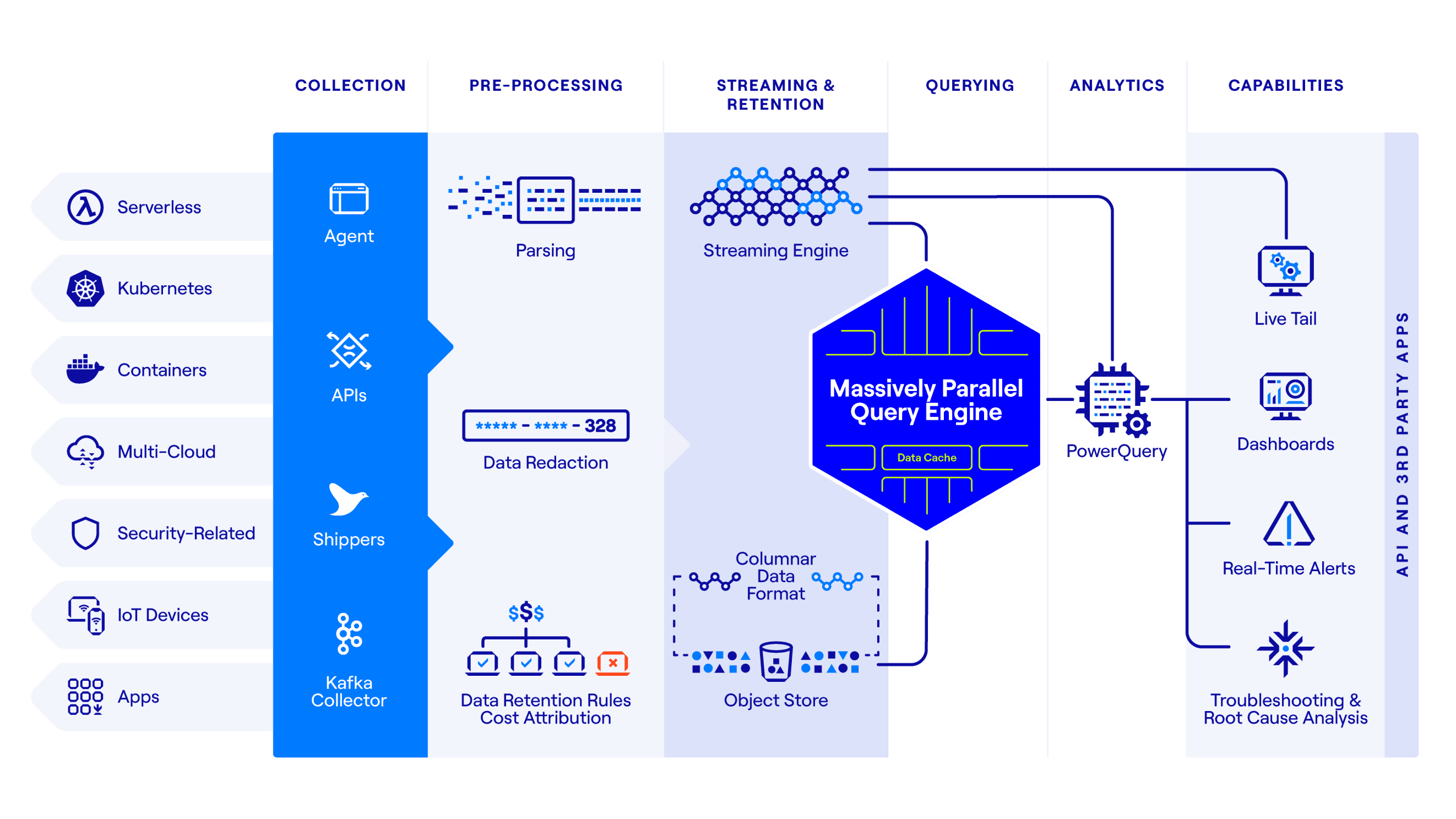
- Cost-Efficient Object Storage: The reliability, scalability and cost of object storage systems such as Amazon S3 can’t be beaten. We use object store to retain historical data, and we have architected the system to break down every barrier in achieving the best-in-class performance.
DataSet dedicates every node in our compute cluster to retrieve data from S3 in parallel, saturating the entire network bandwidth to fetch compressed data in the most efficient way possible. The result is the speedy query performance irrespective of the state of data – streaming or historical, fetched from S3. - Sophisticated Analytics Using PowerQuery: Go beyond data exploration and transform data with DataSet PowerQuery, a rich set of commands to filter, perform computations, extract new fields on the fly, and create groupings and statistical summaries.
Live Data is Multipurpose
Real-time analytics of all data across all time periods powers multiple use cases:
- Full-stack Log Analytics: Instantly aggregate, search and analyze log data across the entire stack. No matter where an anomaly occurs, you can detect, triage, root cause and resolve with DataSet.
- DataSet as a Data lake: DataSet breaks data silos and enables customers to bring all their data and drive collaboration among engineering, DevOps, and security teams, reduce time to problem resolution, and make data-driven decisions and actions.
Many organizations limit data due to high cost, scalability issues or unsupported data sources. While ingesting and retaining all the data might be cost-prohibitive with legacy solutions, throwing away data creates blind spots and compliance challenges. DataSet enables customers to keep all of their data without breaking the bank for as long as they need it. Our customers use DataSet to avoid blind spots, meet compliance requirements and minimize the total cost of ownership. - Long Term Retention: DataSet Hindsight enables our customers to keep their data for as long as they wish and only pay when they query. Whether months or years, DataSet retains live data searchable in real-time. DataSet provides flexibility using DataSet-hosted or customer-managed, low-cost S3 storage.
Alternative solutions require you to create support tickets, take up to 72 hours to make only the partial data available for search. Legacy solutions freeze data into cold or frozen tiers with high retrieval times, making it useless to get insights in real-time. With DataSet’s Live Data Analytics Platform, all your data is instantly available – it doesn’t matter where the data resides or when the data was ingested.
Experience DataSet
Try fully-featured DataSet free for 30 days and immediately start getting value from your data.
Join leaders and builders at DataSet, industry experts, and our customers to learn how they bring live data to decisions and actions; register here.
Want to work with us? We are hiring for multiple roles.
